Jak z blogu vytvořit podcast pomocí AI
Zveřejněno: 2022-03-22Podcasty jsou dnes velice moderní. Lidé nemají čas číst noviny a blogové příspěvky, ale raději si pustí nejnovější zpravodajství či zajímavé rozhovory v audio podobě. Rád bych se podělil o jednoduchý postup, v kterém si ukážeme, jak z příspěvků na vašem blogu jednoduše pomocí modelů umělé inteligence vytvořit audionahrávky.
Tldr
V tomto článku si ukážeme, jak články na blogu napsaném v Next.js, které se automaticky buildují ze souborů json, automaticky pomocí GitHub Actions a Microsoft Azure Speech Services převést na audionahrávky.
Prerekvizity
Aby se vám povedlo celým procesem projít, budete potřebovat:
- mít blog, který běží na node.js
- mít subscription na Azure
- mít účet na GitHubu
Cena řešení
Text budeme syntetizovat pomocí jazykového AI modelu od společnosti Microsoft, který je poskytnut v rámci služeb Azure Cognitive Services, konkrétně Speech Services. Služba nabízí FREE úroveň do počtu 500 000 převedených znaků za měsíc. V mém případě je tato možnost dostačující a pro osobní blog vhodnou.
Více informací ohledně ceny naleznete na: https://azure.microsoft.com/en-us/pricing/calculator/.
Podpora cizích jazyků
Pro službu Azure Speech Services, specificky Text to Speech jsem se rozhodl především z důvodu kvalitní podpory českého jazyka.
Službu jsme ozkoušel v DEMO prostředí na stránkách služby: https://azure.microsoft.com/en-us/services/cognitive-services/text-to-speech/#features.
Architektura projektu
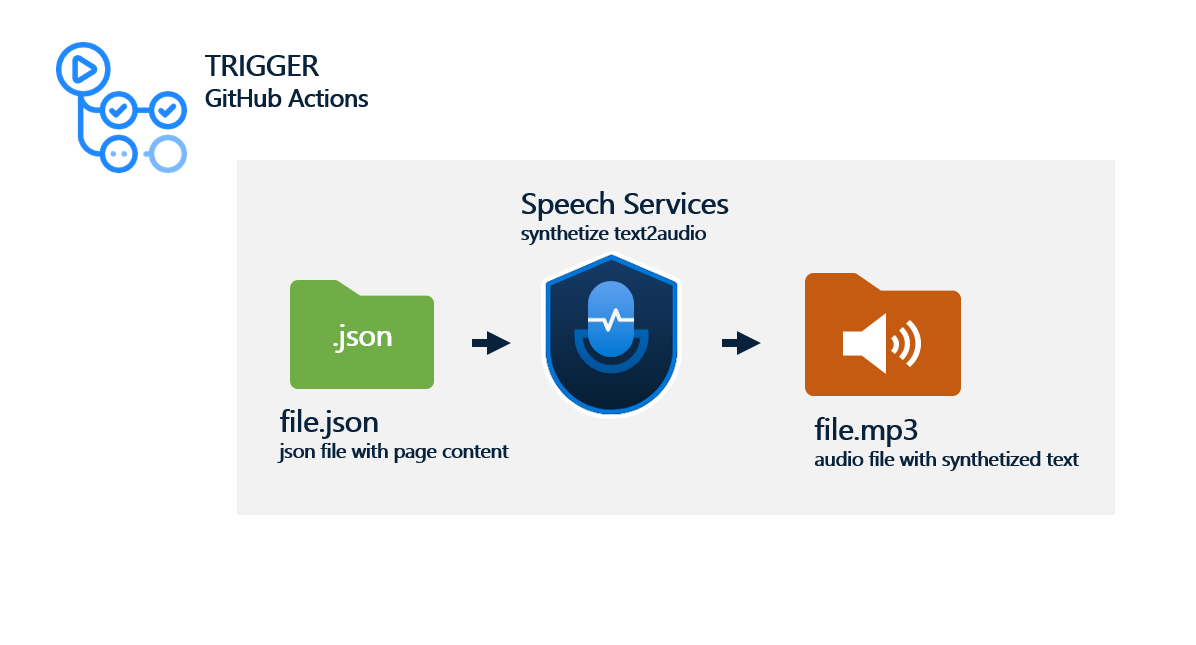
Trigger
Rozhodl jsem se, že službu budu spouštět pomocí GitHub Actions a to hned z několika důvodů:
- Proces odesílání a přijímaní syntetizovaných dat nepoběží u mne na PC, nebude ho zbytečně zatěžovat a nebude závislý na prostředí
- Díky GitHub Actions mohu efektivně a jednoduše uchovávat secrety s bezpečnostně citlivými údaji
- Budu mít přehledný log úspěšných a neúspěšných procesů díky historii GitHub Actions
name: 🔊 Text2Speech
on: workflow_dispatch
jobs:
synthetize:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Install modules
run: yarn
- name: Run text2speech script
run: yarn text2speech ${{ secrets.SPEECH_KEY }} ${{ secrets.LOCATION_REGION }}
- uses: stefanzweifel/git-auto-commit-action@v4
with:
commit_message: Synthetized text to mp3 files
Popis procesu
- Skript přečte veškerý obsah souborů json ve specifické složce
- Pomocí Azure Speech SDK vytvoří žádost o syntetizaci s danými parametry
- Vytvoří a zapíše do souboru audionahrávku
// importuje potrebne knihovny
const sdk = require("microsoft-cognitiveservices-speech-sdk");
const fs = require("fs");
// definuje skrit volany v package.json
module.exports.text2speech = () => {
// process variables
const argv = process.argv;
if(argv[1] === "" || argv[2] === ""){
console.error("ERROR: Set up SPEECH_KEY and LOCATION_REGION!");
return;
}
allJsons(argv[1], argv[2]);
// read and serialize all json foles to json object in the specific folder
function allJsons(SPEECH_KEY, LOCATION_REGION) {
fs.readdir("_days/", (err, filenames) => {
if (err) {
onerror(err);
return;
}
filenames.forEach((filename) => {
fs.readFile(`_days/${filename}`, "utf-8", (err, content) => {
if (err) {
onerror(err);
return;
}
let contentJSON = JSON.parse(content);
let text = `Vítej u dnešního zamyšlení na Tvé cestě Půstem!\nDnes je ${contentJSON.day} a autorem zamyšlení je ${contentJSON.author}.\n\nÚryvek z Bible\n${contentJSON.quote}\n\nZamyšlení\n${contentJSON.reflexion}\n\nDnešní sekce z Christus Vivit\n${contentJSON.vivit}\n\nZávěrečná modlitba\n${contentJSON.preayer}`;
// console.log(contentJSON.slug + text);
SynthesizeSpeech(text, contentJSON.slug, SPEECH_KEY, LOCATION_REGION);
});
});
});
}
// work with Azure Speech Services
function SynthesizeSpeech(text, filename, SPEECH_KEY, LOCATION_REGION) {
const speechConfig = sdk.SpeechConfig.fromSubscription(SPEECH_KEY, LOCATION_REGION);
// config voice options
speechConfig.speechSynthesisLanguage = "cs-CZ";
speechConfig.speechSynthesisVoiceName = "cs-CZ-AntoninNeural";
// Set the output format
speechConfig.speechSynthesisOutputFormat = 21; // mp3, 96kb
const audioConfig = sdk.AudioConfig.fromAudioFileOutput(`public/audio/${filename}.mp3`);
const synthesizer = new sdk.SpeechSynthesizer(speechConfig, audioConfig);
synthesizer.speakTextAsync(
text,
result => {
synthesizer.close();
if (result) {
// return result as stream
return fs.createReadStream(`public/audio/${filename}.mp3`);
}
},
error => {
console.log(error);
synthesizer.close();
});
}
};
Projekt
Více informací i s historií změn, můžete najít v mergnutém pull requestu v repozitáři projektu.