Raft algoritmus
Zveřejněno: 2022-05-26Raft je paralelní algoritmus konsenzu pro správu a replikaci logů. Poskytuje stejný výsledek jako Paxos protokol. Jeho efektivita je stejná, ale pro běžného smrtelníka jednodušší na pochopení. Proto poskytuje lepší funkcionalitu a snadnější implementaci v různých systémech. Pro zvýšení srozumitelnosti, Raft odděluje jednotlivé klíčové prvky konsenzu (např. volbu lídra, replikaci logů a bezpečnost).
Fungování algoritmu Raft
Jednotlivé fáze Raftu
- volba lídra
- běžný provoz (základní replikace logu)
- bezpečnost a konzistence po změně lídra
- neutralizace starých lídrů
- interakce s klienty
1. Volba lídra
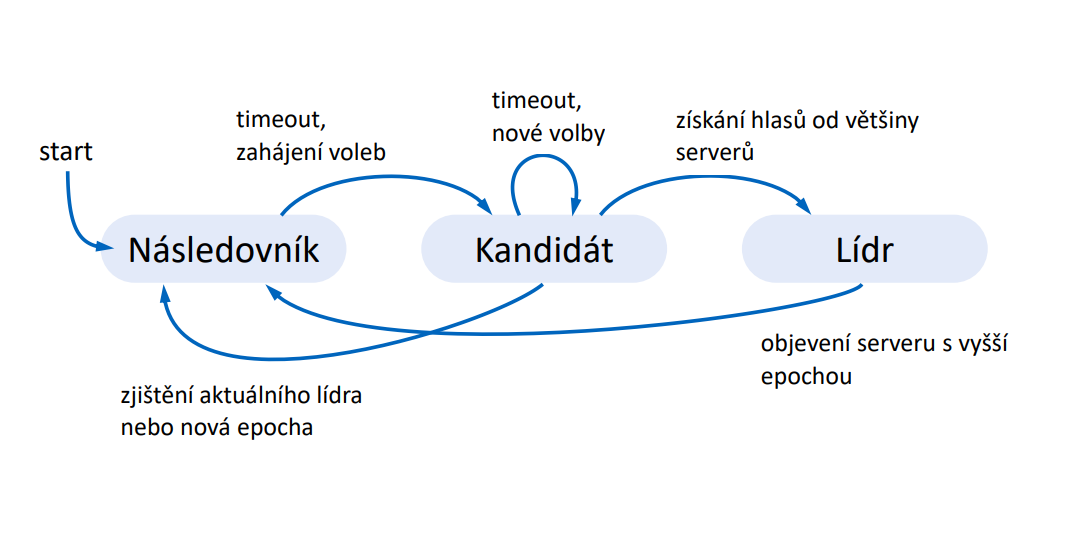
Každé zařízení (server) může být právě v jednom z následujících stavů:
- LÍDR obsahuje požadavky klientů a replikuje log
- NÁSLEDOVNÍK pasivní zařízení, které pouze reaguje na zprávy od jiných zařízení
- KANDIDÁT přechodná role v průběhu volby lídra
Kdy platí, že za běžného provozu existuje pouze 1 lídr a N následovníků.
Epochy
Celkový běh Raftu se rozděluje do jednotlivých časových (logický čas) období, tzv. epoch.
Každá epocha má svoje ID číslo, které se vždy zvyšuje. Každé zařízení i uchovává si své číslo uchovává. Díky tomu se Raft umí vypořádat i s např. vypnutím.
Epocha se skládá ze dvou částí
- volba lídra
- běžný chod
Může nastat epocha bez lídra, jelikož se nepovede lídra zvolit.
Průběh
Na začátku jsou všechna zařízení jako následovníci. Ti očekávají zprávu od lídra nebo od kandidátu na lídra.
Lídři posílají heartbeats, aby si udrželi autoritu.
Jakmile následník neobdrží zprávu do určitého timeoutu, předpokládá že lídr havaroval a iniciuje volbu nového lídra.
Inicializace voleb
Zařízení, které spustí volbu nového lídra:
- zvýší číslo epochy
- změní svůj stav na KADNIDÁT
- zahlasuje pro sebe
- pošle
RequestVotevšem ostatním serverům a čeká na následující stavy- obdrží hlasy od většiny serverů -> změní se na LÍDR a pošle heartbeat ostatní procesům
- přijme zprávu od validního lídra (tedy jiný lídr byl zvolen dříve), vrátí se tedy do stavu NÁSLEDOVNÍK
- nikdo nevyhraje volby, tj. vyprší timeout -> zvýší se ID epochy
Klíčové vlastnosti
- BEZPEČNOST splněna, jelikož může být pouze jeden lídr v každé epoše
- ŽIVOST jeden z kandidátů musí časem vyhrát
- k tomu, aby byl minimalizován kolaps při volbách -> timeouty jsou nastavovány individuálně v určitém intervalu
2. Běžný provoz
Struktura logů
Jedná se o seznam, který v každé položce obsahuj:
- index dané položky
- epochu, ve které daný příkaz vznikl
- samotný příkaz
Logy jsou perzistentní, tedy přežijí havárii (pokud se zařízení vypnou).
Dále existuje tzv. potvrzený záznam (commited). To je takový záznam, který je již potvrzený, tedy uložený již na většině zařízení.
Proces
- klient pošle lídrovy příkaz
- lídr přidá příkaz na konec svého logu
- lídr pošle zprávu
AppendEntriesnásledovníkům a čeká na odpověď - jakmile přijde nadpoloviční většina odpovědí, záznam je potvrzen (commited)
- příkaz se vykoná a odpověď je předána klientovi
- lídr pošle informaci o potvrzení svým následovníkům
- následovníci vykonají daný příkaz
Havárie následovníku se neřeší. Lídr posílá opakovaně zprávu AppendEntries, dokud doručení neuspěje
Konzistence logů
Algoritmus Raft je efektivní především díky konzistenci logů. Tedy pokud se záznamy shodují ve všech pozicích s indexy 1 až n obsahujících záznam se shodným číslem epochy a se shodným příkazem.
Díky návrhu Raftu platí tzv. invarianty raftu.
- Mají-li záznamy logů uložené na různých zařízeních stejný index a epochu, pak obsahují stejný příkaz a logy jsou identické ve všech předešlých záznamech.
- Je-li daný příkaz potvrzený, pak jsou potvrzeny i všechny předchozí logy.
Kontrola konzistence
Při odeslání zprávy AppendEntries zpráva obsahuje i index a příkaz předchozího záznamu, který slouží k validaci.
A pokud se záznam neshoduje, je zápis odmítnut.
3. Změna lídra
Během normálního fungování je zajištěna konzistence. Jakmile ale lídr havaruje, dochází k nové volbě. Je třeba ale efektivně ošetřit danou situaci, aby se předešlo nekonzistenci.
Raft neimplementuje žádnou speciální úklidovou fázi. Raft neustále posílá zprávy, přičemž zpráva je zpráva od lídra. Tedy lídr má vždy pravdu.
Jak ale tedy ošetřit vyskytlé havárie?
Bezpečnost
Prvně si je třeba obecně stanovit, co to znamená bezpečnost.
Obecně nutná bezpečnost pro garanci replikace je to, že jakmile je příkaz ze záznamu logu vykonán některým zařízením, nesmí žádné jiné zařízení vykonávat jiný příkaz pro stejný záznam.
Tedy než něco vykoná dané zařízení, musíme si být jisti, že jiné zařízení nevykoná místo tohoto příkazu něco jiného.
Tohoto bezpečnostního požadavku dosáhneme pomocí tzv. Bezpečnostního invariantu Raftu. Jakmile lídr prohlásí záznam v logu za potvrzený, jakýkoliv budoucí lídr bude mít tento záznam ve svém logu. Díky tomu platí:
- lídři nikdy nepřepisují záznamy ve svých lozích, pouze je přidávají
- pouze záznamy v logu lídra mohou být potvrzeny
- záznamy musí být v logu potvrzeny předtím, než jsou vykonány na daných zařízeních
Zpřísnění výběru lídra a nové pravidlo pro potvrzení
PRVNÍ PODMÍNKA: Jelikož dosavadní logika fungování Raftu bezpečnostní invariant negarantuje, snaží se Raft zvolit lídra, který má nejúplnější log. Tj. epochu nejvyšší epochou případně pokud mají stejnou epochu, tak s nejvyšším indexem.
DRUHÁ PODMÍNKA: Aby lídr požadoval záznam za potvrzený musí být:
- záznam uložený na většině serverů (známe podmínku)
- také alespoň jeden nový záznam z lídrovy aktuální epochy na většině serverů (podmínka navíc)
Jakmile je tato i předchozí podmínka splněna, již lze prohlásit invariant a bezpečnost za splněnou.
Oprava logu následovníků
Nový lídr musí udělat logy následovníků konzistentních se svým logem. Tj. smazat přebytečné záznamy a doplnit chybějící záznamy.
V praxi se oprava implementuje tak, že lídr určuje proměnnou nextIndex pro každého následovníka:
- index další záznamu logu, který by měl být odeslán následovníkovi
- inicializován na 1 + index poslední záznam lídra
Pokud kontrola konzistence AppendEntries selže, sníží nextIndex o jednu a zkusí znovu.
V podstatě prvně zjistí, jak moc do historie se musí vrátit. Tam vše ustřihne a naplní zásobník novými logy.
4. Neutralizace starého lídra
Je třeba řešit situaci kdy zhavaruje lídr. Např. se od něho opozdí zprávy. Později opět ožije. Jak ale zjistí, že již dále není lídrem?
Řešením je to, že zařízení nepřijme zprávu s nižší epochou. Přesněji pokud zařízení zachytí zprávu s nižší epochou od starého lídra, pošle mu zpátky zprávu s informací, že si má zvýšit epochu a zrušit status lídra.
5. Interakce s klienty
Protokol klienta
Klienti posílají příkaz lídrovi. Pokud zařízení není lídrem, pošle zařízení klientovi současného lídra a ten již ví na koho směřovat zprávu.
Jediné vykonání
Lídr může havarovat poté, co už ale vykonal příkaz před odesláním odpovědi. Existuje tedy riziko opakovaného vykonání příkazu.
Řešením je, že každý příkaz má jedinečné ID příkazu. Při přijmutí příkazu, pak vždy lídr zkontroluje zdali již ID není na zařízení uloženo.
Závěr
Algoritmus Raft je jeden z nejmodernějších (2014) a vysoce využívaných paralelních algoritmů. Je implementován např. v distribuovaných databázích, které dokážou běžet nad clusterem.
Pro hezké otestování a lepší pochopení algoritmu existuje hezká stránka s přehledem a vizualizací raft.github.io.
Reference
[1] In Search of an Understandable Consensus Algorithm (Extended Version) | Diego Ongaro and John Ousterhout (Stanford University)
[2] Algoritmus Raft (Michal Jakob CTU FEL) | slideshow, přednáška
Literatura
Ongaro, D. and Ousterhout, J.K., 2014, June. In search of an understandable consensus algorithm. In USENIX Annual Technical Conference. link